Your $200 Lambda Could Create $10K in CloudWatch Logs
The CloudWatch Lambda Log Blowout

“You have this little tiny Lambda, and everyone is worried about right-sizing the Lambda… and at the same time they’re just shoving log files into CloudWatch forever…No retention. No nothing.” – David Schwartz – CloudFix
CloudFix is an excellent tool for automating your AWS costs. To be used most effectively it should exist within a culture of cost optimization in your organization. At CloudFix, we certainly have cultivated that culture for ourselves. We were recently having a meeting looking at the CloudFix recommendations for CloudWatch Log Retention. In this meeting, we found a Lambda function which cost $205/yr. What a bargain! But, the CloudWatch Logs produced by this Lambda function had an annualized cost of more than $10K! Ouch!
Luckily, CloudFix brought this to our attention, and we were able to notify the function owner, who was able to make the necessary changes. They say a picture is worth 1000 words. Well, in this case a screenshot is worth $10,000. So, here’s two of them to show you what we saw.
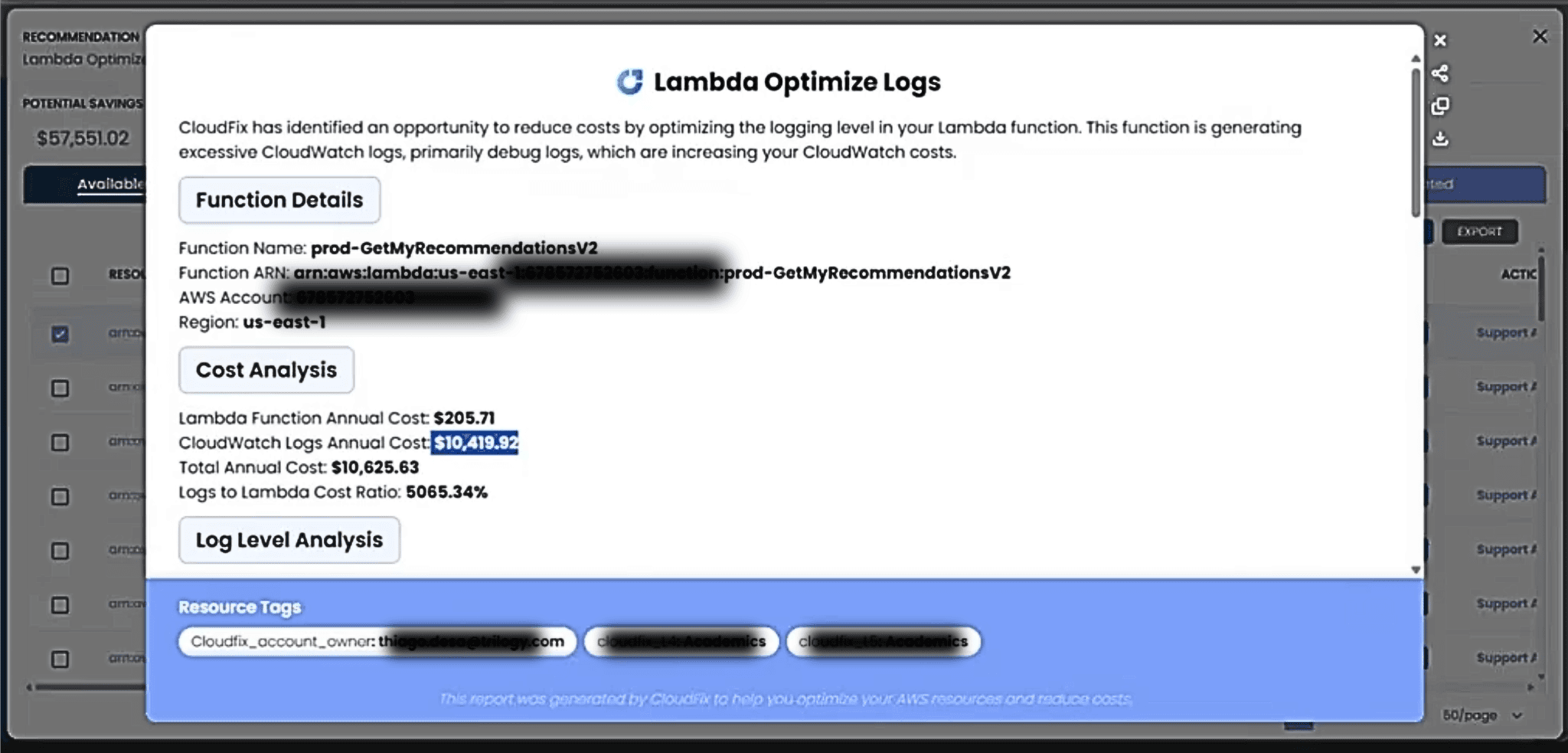
Lambda Logs Cost Analysis
In the rest of this blog post, we are going to talk about:
- What should logs cost?
- How do we get CloudWatch Logs cost blowouts like this?
- Pricing Implications
- CloudFix Automation for Monitoring and Reducing CloudWatch Logs Costs
- Final Tips
What should logs cost?
The Log Retention Finder/Fixer produces a fascinating metric – the “Logs to Lambda Cost Ratio.” Looking at the screenshots, the ratio for this is 5000%, or 50x. Unless you are in a highly regulated industry and required to keep detailed CloudWatch logs forever, this ratio seems wrong.
In technology, a well-balanced IT infrastructure might allocate 40% for compute resources, 30% for networking, 20% for storage, and 10% for monitoring. In the restaurant industry, the ideal ratio is prime costs (food + labor) should be 60-65% of sales. Finance personality Dave Ramsey advises that the total value of “everything you own that has a motor in it” (i.e. cars, boats, and other rapidly depreciating assets) should be no more than 50% of your annual income. If you made $50K per year but drove a $250,000 Rolls Royce, this ratio would be wrong.
What is the right ratio? Of course, the unsatisfying but true answer is “it depends”. In this case, it depends on your regulatory requirements and company culture. But, whatever it is, you don’t want to be spending more than this without good reason.
How does this happen?
A Sample Lambda Function
Consider the following Lambda function:
import json
import logging
from datetime import datetime
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""A Lambda that logs way too much for simple processing"""
# Log everything about the incoming request
logger.info(f"Event: {json.dumps(event)}")
logger.info(f"Started at: {datetime.now()}")
# Process records with excessive logging
records = event.get('Records', [])
logger.info(f"Processing {len(records)} records")
for i, record in enumerate(records):
logger.info(f"Record {i+1}: {json.dumps(record)}")
# Extract and log user data
user_data = record.get('dynamodb', {}).get('NewImage', {})
logger.info(f"User data: {json.dumps(user_data)}")
# Log each field individually
for field, value in user_data.items():
logger.info(f"Field {field}: {json.dumps(value)}")
# Validate email with verbose logging
if field == 'email':
email = value.get('S', '')
logger.info(f"Validating email: {email}")
logger.info("Email valid!" if '@' in email else "Email invalid!")
# Log completion
logger.info(f"Completed at: {datetime.now()}")
response = {'statusCode': 200, 'processed': len(records)}
logger.info(f"Response: {json.dumps(response)}")
return response
This may be a facetious example, but it illustrates the point. If you are printing out every record, every field in the user_data, and simple operations link email address validation at the INFO level, the INFO level will get completely full. Especially with generative AI, it is easy to tell your AI agent of choice to ‘add very verbose logging’ and…you get exactly what you asked for.
What are logging levels anyway?
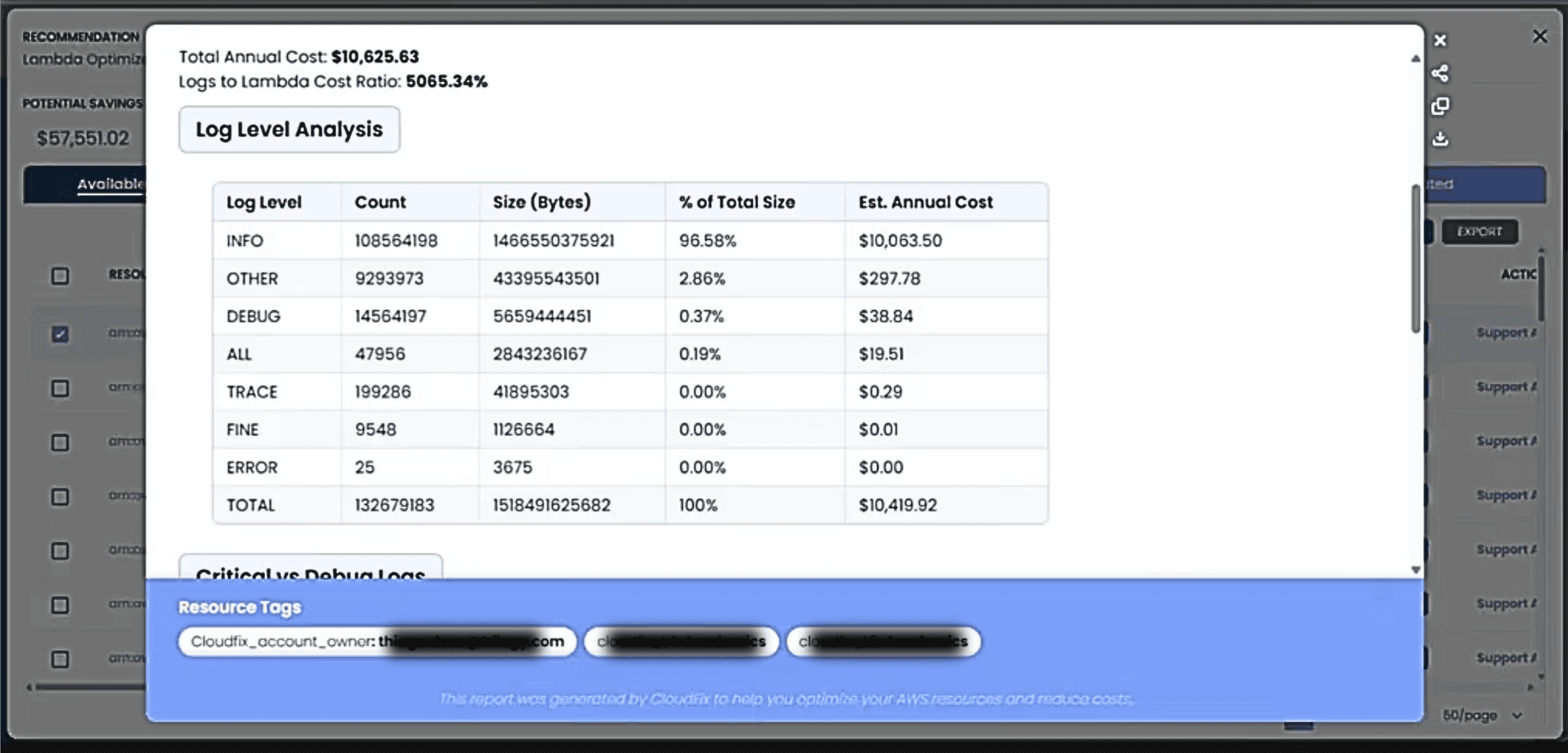
The figure below shows a logging levels analysis.
Note that 95% of the logging costs for this particular Lambda function were “Info” level. Logging frameworks typically define a clear hierarchy of severity levels:,
- DEBUG: Detailed data for troubleshooting.
- INFO: General operational events.
- WARNING: Potential issues that are not errors.
- ERROR: Problems preventing specific functions from working.
- CRITICAL: Severe issues that may lead to system failure.
Using Log Levels Effectively
Follow the hierarchy of logging levels in your code. At the CRITICAL level, you should log just enough to be compliant. ERROR and WARNING can flag potential non-error issues. For example, if a dependent service needs to be retried a few times before it works, this may be useful at the WARNING level. INFO can print things like the input and output to major functions, and DEBUG can print everything. By default, logging sets at the WARNING level.
Note: Making your code adhere to a defined hierarchy of logging levels used to be extremely tedious. This is a perfect use case for generative AI. If you are using Cursor, create a + which encodes your logging structure.
When you are developing, you can set it at INFO by default. If you are tracking down a problem, set it to DEBUG. Once the service is running well, set it to a higher level, e.g. ‘ERROR’.
You can put the log level as an environment variable within your AWS CloudFormation templates, as in the following code:
AWSTemplateFormatVersion: '2010-09-09'
Description: 'Lambda function with configurable logging level'
Parameters:
LogLevel:
Type: String
Default: INFO
AllowedValues:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
Description: 'Logging level for the Lambda function'
Resources:
ProcessingLambdaFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub '${AWS::StackName}-processing-lambda'
Runtime: python3.9
Handler: lambda_function.lambda_handler
Environment:
Variables:
LOG_LEVEL: !Ref LogLevel
# Other environment variables...
Role: !GetAtt LambdaExecutionRole.Arn
Timeout: 300
MemorySize: 128
See that there is an environment variable, LOG_LEVEL, which is passed to the function at deploy time. The code can then reference this.
If you want to make your log level even more flexible, so you can change the log level without redeploying, you can also store the log level in AWS Systems Manager Parameter Store.
import boto3
import logging
import os
def get_log_level():
"""Get log level from Parameter Store with fallback"""
try:
ssm = boto3.client('ssm')
parameter_name = f"/myapp/{os.getenv('ENVIRONMENT', 'dev')}/log-level"
response = ssm.get_parameter(Name=parameter_name)
return response['Parameter']['Value'].upper()
except Exception as e:
# Fallback to environment variable or default
return os.getenv('LOG_LEVEL', 'INFO').upper()
Pricing Implications
Amazon CloudWatch Logs pricing is based on three main factors: data ingestion, storage, and analysis. After a free tier of 5 GB per month, you pay $0.50 per GB for log data ingested and $0.03 per GB per month for log data stored in the US East (N. Virginia) region. Charges for log analysis using CloudWatch Logs Insights are $0.005 per GB scanned. There are no upfront commitments or minimum fees; you are billed monthly for your actual usage. Additional features like real-time streaming (Live Tail) and data masking incur extra charges. The total cost can vary significantly depending on how much log data your AWS resources generate and how long you retain it.
By default, CloudWatch retains all log data indefinitely. Or, as the great Sherif Squidman Palledorous said, for-ev-er.

Source: Giphy
In other words, logs are never deleted unless you set a custom retention policy. This default setting can result in ongoing, accumulating storage charges, as you will continue to pay for every gigabyte stored for as long as the logs exist. Many AWS services, such as Lambda, create log groups with this indefinite retention by default. To avoid unnecessary long-term costs, it’s important to review and set appropriate retention periods for your log groups, deleting logs that are no longer needed. Otherwise, you risk paying for log storage forever, even for data that may no longer be relevant to your operations.CloudWatch Logs pricing is determined by three primary factors: data ingestion, data storage duration, and log analysis.
CloudFix Automation
CloudFix has two Finder/Fixers affecting logging.
For CloudWatch log groups costing more than $100/year, a recommendation is made to adjust the retention policy.
- CloudWatch Optimize Retention Blog Post
- CloudWatch Optimize Retention Feature Page
- CloudWatch Optimize Retention Support Article
Changing the retention policy is helpful at not holding on to more logs than necessary. But, this does not get to the root cause – accumulating too many logs in the first place.
The Lambda Optimize Logs Finder/Fixer shows the amount of logs produced, broken down by level. This can provide good guidance for how to adjust your logging.
Final Tips
Things to remember:
- Make sure that your logging is compliant at EVERY information level.
- The default level should be WARNING.
- CloudWatch Log Retention Policies turn an unbounded cost into a limited cost. Use these.
- Use automation to monitor all of your AWS accounts for Log Retention policies.
- Analyze the distribution of logging levels for each Lambda function.