Introducing CloudFix’s Newest Addition: The EMR Instance Optimizer


Hey AWS enthusiasts and cost-conscious developers! We’ve got some electrifying news that’ll spark your interest and ignite your AWS budget optimization efforts. Today, we’re excited to announce the latest breakthrough in our suite of automated solutions at CloudFix – the EMR Instance Optimizer!
As a leader in cloud resource management, CloudFix is always on the hunt for new ways to help you streamline your AWS spending. Our innovative collection of Finder/Fixers has already paved the way for significant savings across various AWS services. But we didn’t stop there.
In this blog post, we are going to discuss:
- What is Elastic Map Reduce, and how is it priced?
- What leads to EMR overspend?
- How does the EMR finder/fixer work?
- Using CloudFix for Automated Savings
Lets jump into the details and learn more about Elastic Map Reduce.
What is Elastic Map Reduce, and how is it priced?
Elastic Map Reduce (EMR) is a cloud-based big data processing service offered by Amazon Web Services (AWS). It allows you to process large amounts of data using popular frameworks such as Apache Hadoop, Apache Spark, and Presto.
The name, Elastic Map Reduce, comes from the MapReduce algorithm, which is a strategy for large scale parallel processing on a class of workloads commonly classified as embarrassingly parallel. For example, generating a set of preview images for an image gallery is as simple as generating a preview image for each image in the gallery – this would be embarrassingly parallel. Another example would be a simulation, e.g. simulating the outcome of a card game; in the Map step, the game is initialized with a particular starting configuration and simulated, and in the Reduce step the average result across all simulations is calculated.
In addition to the Algorithm, Map Reduce was also part of the Hadoop project, which emerged out of Yahoo in the mid 2000’s. A great history of Hadoop can be seen in this article here, A Brief History of Big Data. Hadoop, which was eventually moved to the Apache Software Foundation, is still used today, although it has mostly been superseded by Apache Spark or Apache Hive, and Presto. Hadoop, although open source, was quite difficult to configure. You needed a dedicated cluster, and getting the correct version of every library, the Java Virtual Machine, and all of the required dependencies was tricky to manage.
This difficulty in setting up Hadoop was Amazon’s opportunity. AWS launched Elastic Map Reduce in 2009. In AWS terms, this is an ancient service. Given the AWS services which existed at the time, namely S3, EC2, SQS, and SimpleDB, these services were the building blocks on the higher level offerings. Elastic Map Reduce was one of the first high level managed services. Notably, Amazon RDS launched around the same time. EMR has continued to evolve, most notably to expand to support other cluster compute applications such as Apache Spark, Apache HBase, and Apache Hive, and Hue.
A small overview of new EMR features include:
|
Feature |
Launch Date or Year |
|
Spot Instances Integration |
2011 |
|
EMR File System (EMRFS) |
2014 |
|
Support for Apache Spark |
June 2014 |
|
Integration with AWS Glue Data Catalog |
2017 |
|
EMR Notebooks |
November 2018 |
|
Automated Provisioning with AWS Lake Formation |
2019 |
|
Serverless Option (EMR on AWS Outposts) |
2019 |
|
EMR Studio |
December 2020 |
|
Amazon EMR on EKS |
December 2020 |
|
EMR Containers |
December 2020 |
|
Managed Scaling |
Evolved over time |
|
Security Enhancements (Encryption, IAM Integration) |
Evolved over time |
|
Fine-Grained Access Control |
Evolved over time |
|
Cross-Account Cluster Access |
Evolved over time |
EMR Pricing
The pricing for EMR is based on a few key factors:
- Instance Types: EMR allows you to choose from a variety of instance types, each with its own pricing structure. You can select instances optimized for compute, memory, storage, or a balance of all three, depending on your specific needs.
- Instance Hours: With EMR, you pay for the number of hours your instances are running. This means that you have full control over when to start and stop your clusters, allowing you to optimize costs by only paying for the resources you actually need.
- Additional Services: Depending on your use case, you may need additional services such as Amazon S3 for storing input and output data, or Amazon DynamoDB for real-time data processing. The pricing for these services is separate from the EMR pricing and should be taken into account when calculating your overall costs.
To more succinctly summarize, the compute portion of EMR jobs is the EC2 cost, plus an EMR premium, which varies based on the instance type. It is on average a 22% premium, but can be as low as 12% and as high as 27%. For details, see the EMR on Amazon EC2 Pricing Page. Note that you can also run EMR on EKS, on Serverless,
What leads to EMR overspend?
EMR overspend is similar in nature to EC2 overspend. As stated earlier, EMR is effectively a preconfigured cluster of EC2 instances. The size of these instances was chosen at a given point in time, based on criteria which were appropriate at the time. For example, a user may have chosen an oversized instance to make sure that their job worked, with the intention of right-sizing it later. However, once the job is done it is easy to move on to the next task. Engineers are busy enough as it is, and they often are not properly incentivized to optimize for costs. Another possibility is that the cluster instances were sized for a particular type of workload, and the nature of the workload itself has changed. For example, the simulation code over time may use less memory than before, and therefore a compute-optimized instance or general instance may be more cost effective than a memory optimized instance.
In any case, the benefits of right-sizing EMR instances are similar to the benefits of right-sizing EC2 instances, but the payoff is multiplied by the size of the cluster. For example, if you are running 10 EMR instances of type m7a.24xlarge to m7a.16xlarge, you would realize the following savings:
|
EC2 Price |
EMR Price |
Hourly Price |
Per Month |
|
|
m7a.16xlarge |
$3.71 |
$0.93 |
$4.64 |
$33,384.96 |
|
m7a.24xlarge |
$5.56 |
$1.39 |
$6.96 |
$50,077.44 |
|
Savings on retyping 10 instances for 1 month |
$16,692.48 |
The “Per Month” cost is calculated as 10 instances running 24 hours per day for a 30 day month. Note that the retyping of an instance is to the next smallest size. This is a 33% drop in price!
How does the EMR Instance Optimizer Finder/Fixer work?
The EMR instance optimizer Finder/Fixer works though a tried and true algorithm. Namely:
-
- Use the Cost and Usage Report to find EC2 instances belonging to EMR clusters
- Query Compute Optimizer for potential savings
- Exclude recommendations of rightsizing to nano/micro instances, exclude high risk recommendations, and exclude recommendations where the potential savings are < 2%
- If savings meet this criterion, the user must execute the change. At present, this is called a Manual Fixer in that the fix must be manually executed by the user, rather than utilize through AWS Change Manger.
- Realize cost savings!
It is a straightforward algorithm, and you can read more details in our EC2 Right-sizing Finder/Fixer blog post. The key part is that CloudFix will surface a recommendation. The data in the recommendation include an Instance ID, Emr Cluster Id, and the target instance type.
For Elastic Map Reduce, you cannot dynamically change the type of the EC2 instance. Instead, you should terminate your existing cluster, change the instance type, start a new cluster, and direct future jobs to the new cluster. If your EMR is managed by a CloudFormation template, it will look similar to the following:
AWSTemplateFormatVersion: '2010-09-09'
Description: 'AWS CloudFormation Sample Template: EMR Cluster'
Resources:
MyEMRCluster:
Type: 'AWS::EMR::Cluster'
Properties:
Name: MyEMRCluster
ReleaseLabel: emr-6.4.0
Applications:
- Name: Hadoop
- Name: Spark
Instances:
MasterInstanceGroup:
InstanceCount: 1
InstanceType: m5.4xlarge
Market: ON_DEMAND
CoreInstanceGroup:
InstanceCount: 10
InstanceType: m5.4xlarge
Market: ON_DEMAND
JobFlowRole: EMR_EC2_DefaultRole
ServiceRole: EMR_DefaultRole
VisibleToAllUsers: true
Outputs:
ClusterId:
Description: The Cluster ID
Value: !Ref MyEMRClusterUsing CloudFix for Automated Savings
Using CloudFix is the easiest way to realize automatic savings for your EMR clusters. Within the CloudFix interface, this finder/fixer is called “EMR Optimize Instances” tab. Once you have found a recommendation, you must update the cluster configuration and relaunch the cluster with the suggested new instance type.
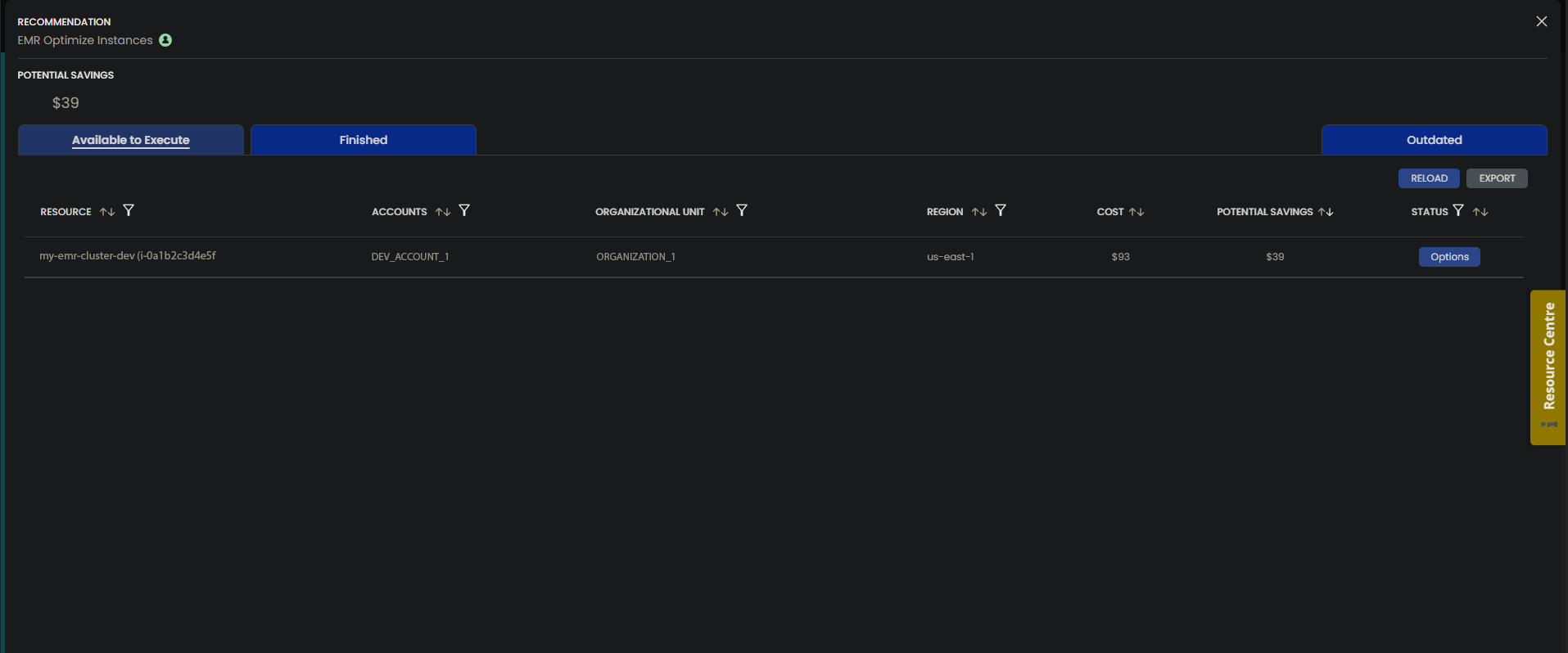
An available recommendation, click to learn more
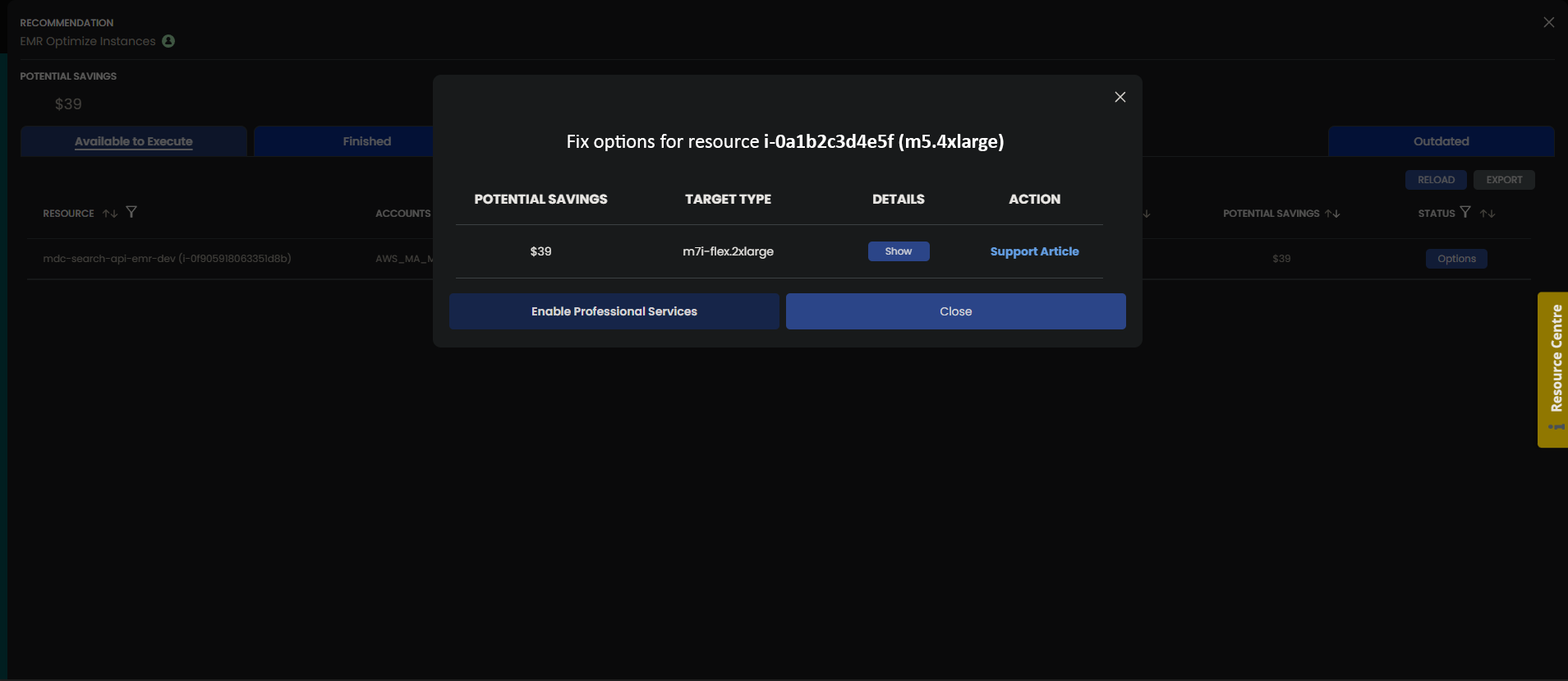
Click on the “Show” button in the Details Column
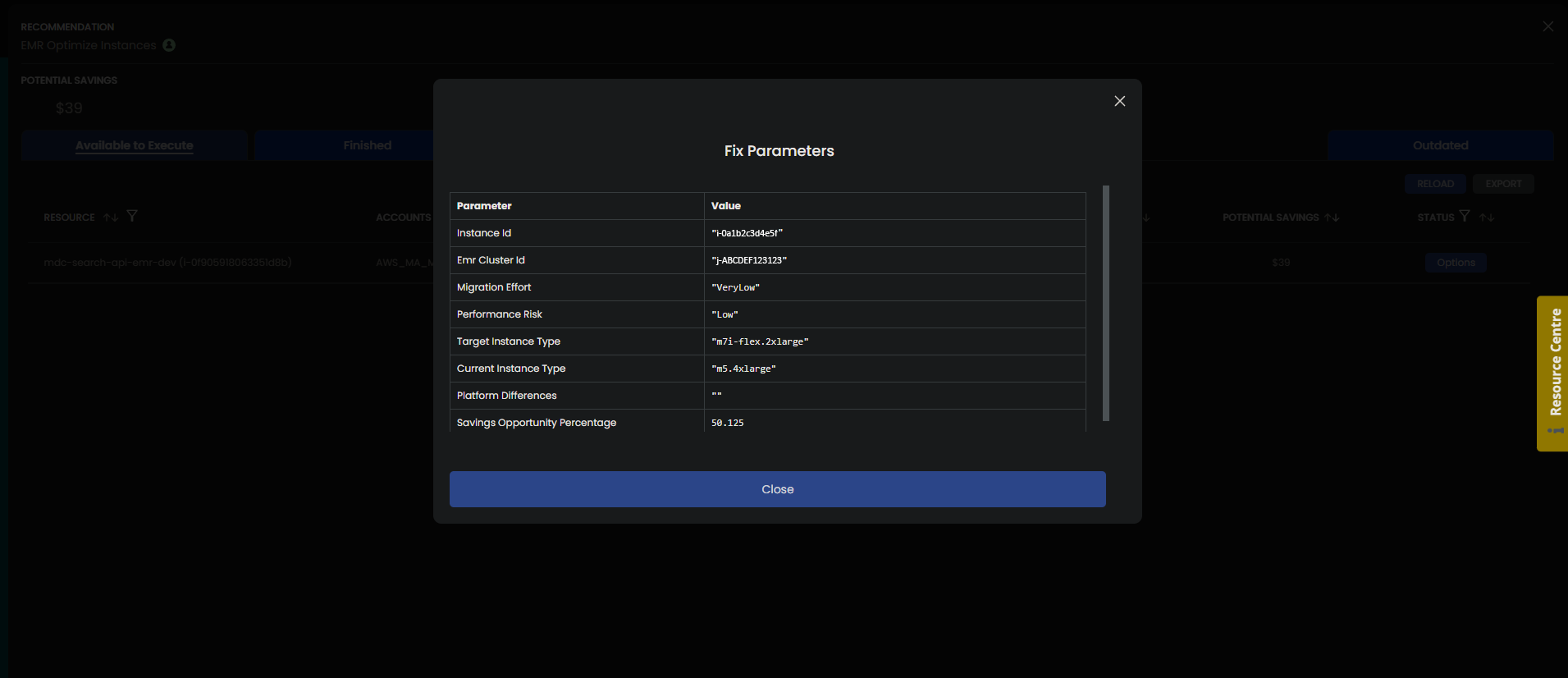
The details of the retyping recommendation
Once you implement this recommendation, you will start saving on your AWS Elastic Map Reduce cluster costs, while maintaining the same capacity to process your workloads! Enjoy the savings!
Related Articles
-
<
- AWS Cost Optimization: The Complete Guide to Lowering Your Cloud Bill (2026)
- AWS Cost Optimization Tools: The Complete Comparison Guide (2026)
- Find Idle AWS Transfer Family Endpoints
- CloudFix Finder: SageMaker Rightsize Instances (Manual Fix)
li>RightSpend vs ProsperOps (Flexera): The Independent EC2 Discount Alternative