OpenSearch EBS Volumes Overprovisioned? Cut Storage Costs 50%


400 million cups
– the amount of coffee that Americans drink every day
Many of us depend on a single numerous cups of coffee to stay productive and get things done. While we rely on coffee to perk us up, however, it can sometimes slow us down. Who hasn’t stared at the coffee shop board, frozen by analysis paralysis, trying to decide between all the different types and sizes? It’s a fraught choice: order too much and you waste money and coffee (never a good thing), but order too little, and you risk snoozing on your desk in the early afternoon, which is also not ideal.

Too Many Coffee Choices, generated by the Midjourney Generative Art AI
You can probably see where we’re going with this. AWS, like your local coffee shop, lets you customize your “order” almost endlessly – but it also makes it easy to get too much or too little of a given product or service. That’s why we talk a lot about right-sizing AWS services (like here) and what brings us to our topic today: how to balance size and cost in OpenSearch EBS volumes. Let’s dig in – or, shall we say, drink up.
Table of contents
- Hot storage, EBS volumes, and gp2/gp3: Behind the scenes with OpenSearch storage
- Why your EBS volumes are overprovisioned: The trap of “I’ll adjust it later”
- How to save 50% or more by right-sizing EBS volumes
- 4 steps to manually right-sizing EBS volumes for OpenSearch
- Right-size your OpenSearch EBS volume costs easily and automatically with CloudFix
Hot storage, EBS volumes, and gp2/gp3: Behind the scenes with OpenSearch storage
OpenSearch is a document indexing and searching platform. It can ingest and search a large amount of both machine-generated data like logs and unstructured document data. OpenSearch is extremely fast and useful. It makes it easy to create analytics solutions and add text search functionality to an application or website.
Technically, OpenSearch is the open-source software and the AWS service that runs OpenSearch is the Amazon OpenSearch Service. In practice, people refer to both simply as “OpenSearch.” The OpenSearch Service also can run ElasticSearch, which was the original version of the software. This VentureBeat article, aptly titled Once frenemies, Elastic and AWS are now besties, does a great job of discussing the relationship between OpenSearch and ElasticSearch. If you’re hungry for even more, my colleague Rahul and I chatted about it on an early episode of our AWS Made Easy livestream as well.
Quick side note
In January, AWS released a really neat product called OpenSearch Serverless, which Rahul and I covered in an episode of AWS Made Easy. We’re both big supporters of serverless infrastructure, and recommend investigating if OpenSearch Serverless could be a good option for your organization.
Back to standard OpenSearch. In the default AWS OpenSearch product, OpenSearch runs on a cluster of provisioned resources, which uses special instances with the .search suffix, such as t3.small.search. In addition to compute, a cluster requires associated storage. OpenSearch storage is a complicated topic, so let’s do a quick review.
OpenSearch’s fundamental data storage is the index. An index is a data structure that contains documents as well as metadata optimized for searching, filtering, and analysis. The index can hold far more data than can be stored on one machine. So, to make the index searchable as a unit, it’s divided into shards. The shard is the basic unit of storage and retrieval in OpenSearch, and is essentially a smaller, self-contained index. Shards exist on one node of the cluster and are classified as either primary or replica shards. Primary shards can update data, and replica shards make querying faster.
The performance of the OpenSearch cluster is highly dependent on the performance of its underlying storage media; the faster that OpenSearch can access the data, the faster it will run. There are different storage tiers for indices, and a cluster can search multiple indices simultaneously. Hot storage is the tier used by standard AWS OpenSearch data notes and is powered by Amazon EBS volumes. UltraWarm, which is less performant and less expensive than hot storage, uses AWS S3 as the underlying storage media, plus a cache to improve performance. Cold storage is also based on AWS S3, comparable to the S3 Glacier Flexible Retrieval storage class.
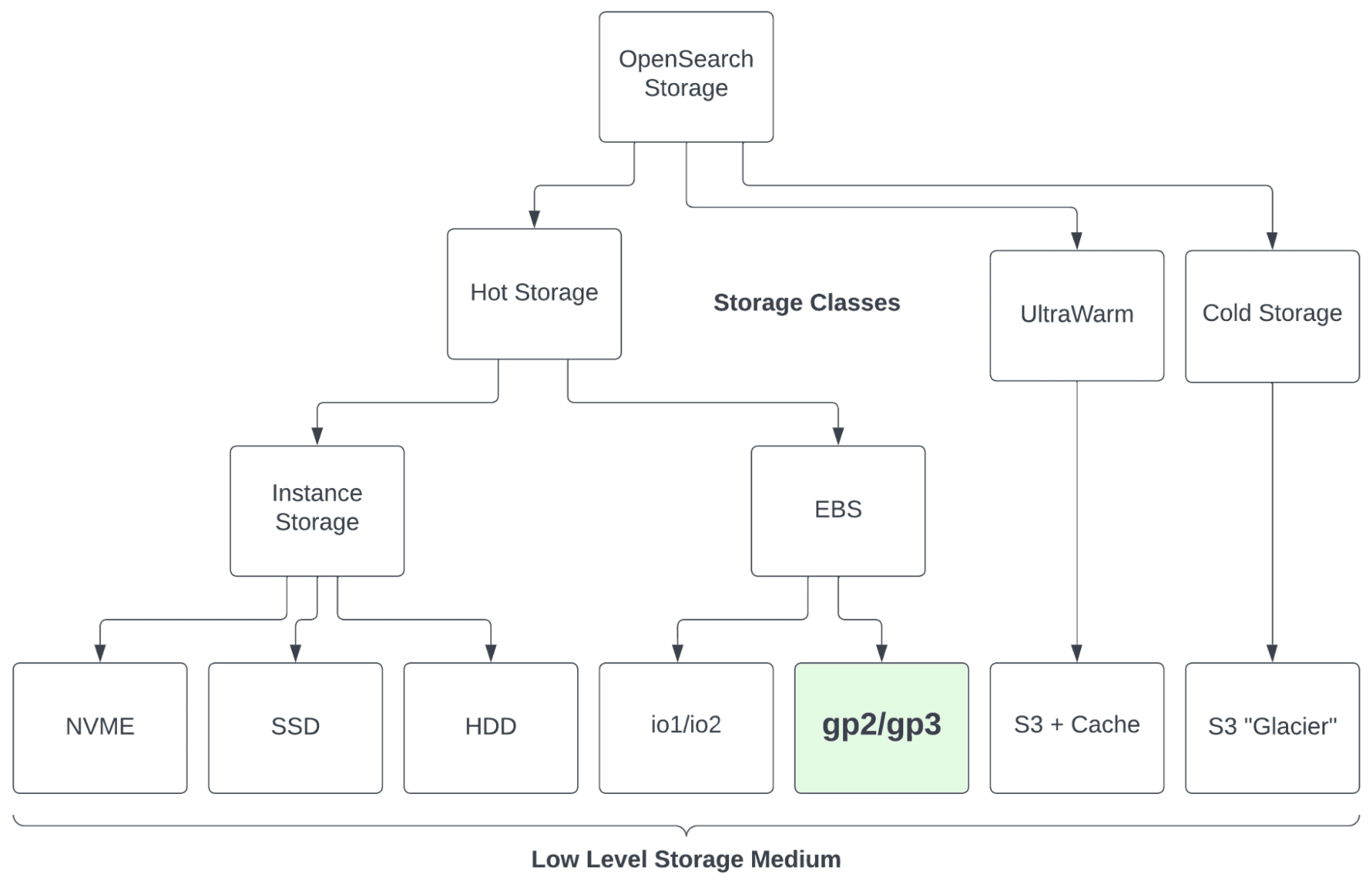
OpenSearch Service storage types
In general, most OpenSearch users rely primarily (or entirely) on hot storage and add some UltraWarm or cold if/when it makes sense. That balance is not the only decision you need to make, though. Within the hot storage tier, you can also decide between EBS volumes and instance storage, and within EBS, whether to use io1/io2 or gp2/gp3.
These choices are pretty straightforward. In almost every instance, you want to use EBS volumes instead of instance storage. While instance storage is fast, it’s not durable, and it will vanish if the instance gets terminated. Similarly, io1/io2 are blazingly fast, but just as blazingly expensive. That level of speed is rarely necessary or worth the cost. Which leaves us with our old favorites, gp2 and gp3. We’ve said it before and we’ll say it again: we love the performance, low cost, and flexibility of gp3. Although it’s slightly less performant and less flexible, gp2 works just fine as well.
Useful aside: The case for gp3
When it comes to EBS volumes, you’d be crazy NOT to use gp3. Why? The key dimensions when creating an EBS volume are size, throughput, and IOPS. WIth gp2, the only dimension you can choose is storage, and then throughput and IOPS scale up proportionally. Likewise, if you need more throughput, you have to pay for more storage and more IOPS. Not very flexible or cost-effective.
With gp3, you can adjust these levers independently, so you get the precise performance that you need and don’t pay for components that you don’t. If your budget is fixed, gp3 will offer better performance. If you need to achieve certain performance criteria, gp3 will do this for less. While gp3 pricing can be a little convoluted, we’ve run the numbers, and gp3 is always the better option. For more on gp3, check out this recording of an AWS Made Easy livestream.
Why your EBS volumes are overprovisioned: The trap of “I’ll adjust it later”
So, if you’re using OpenSearch, you’re probably using gp2 or gp3 as your EBS storage media. Now the question is, why are you using so much of it?
In a nutshell, we end up with too much OpenSearch storage because we’re human.
We still haven’t fully adjusted to the flexibility of the cloud. We’re used to having to decide on the size of resources, like our coffee, and then being stuck with the consequences of that decision. Once that cup’s in your hands, you’re not going back to upgrade to Venti. This has traditionally been true with technology, too. When you buy a computer, especially laptops that aren’t upgradeable, you’re stuck with your chosen specs for the lifetime of the hardware.
This mindset is hard to break. We want to make sure that we have enough if we need it, so we overestimate. It’s tough to truly internalize that you can resize and change most cloud resources at any time.
The second way that being human leads to overprovisioning EBS volumes: procrastination. This is a close personal friend of mine. When you start a project, it makes sense to use larger resources. You want the development experience to be quick, and when you are building, testing, and deploying, the process typically uses more resources than the project will require in its steady state. As a result, we provision a larger instance than we need in the long run, with a mental note that “we’ll adjust it later.” Spoiler alert: we won’t. Once the project is successfully up and running, we move on to the next one, and our original resource remains faster, larger, and more expensive than it needs to be.
How to save 50% or more by right-sizing EBS volumes
EBS volumes for OpenSearch cost considerably more than their standard EBS counterparts. For example, us-east-1 EBS volumes for gp3 cost $0.08/GB, compared to $0.122 when part of an OpenSearch cluster.
Here’s how EBS volumes for OpenSearch are priced as of April 2023 in us-east-1:
|
Type |
Item |
Cost |
|
gp3 |
Storage |
$0.122 GB/Month |
|
gp3 |
IOPS |
3000 Free up to 1024 GiB, or 3 IOPS/GiB free for volumes above 1024 GiB. $0.008/provisioned IOPS above free limits. |
|
gp3 |
Throughput |
125 MiB/s free up to 170 GiB, or +250 MiB/s free for every 3 TiB for volumes above 170 GiB. $0.064/provisioned MiBs over free limits. |
|
gp2 |
Storage + IOPS + Throughput |
$0.135 per GB / month |
|
Magnetic |
Storage + IOPS + Throughput |
$0.067 per GB / month |
|
io1 |
Storage |
$0.169 per GB / month |
|
io1 |
IOPS |
$0.088 per IOPS / month |
For full details, see AWS OpenSearch Service Pricing
Let’s look at an example to see how EBS costs change when we make some strategic adjustments.
Say we have an OpenSearch cluster with 3x hot storage EBS gp3 volumes, each at 800 GiB. Assume that the baseline levels of IOPS and throughput are sufficient for our needs, so we’re only looking at the storage rate. Our data is growing at 15 GiB per month, starting at a 200 GiB baseline. Doing a simple pricing exercise:
|
Month Number |
GB/Node |
Free Space % |
Cost Actual |
Cost at RVS |
$Savings |
%Savings |
|
1 |
215 |
73.13% |
$292.80 |
$123.708 |
$169.09 |
57.8% |
|
2 |
230 |
71.25% |
$292.80 |
$130.845 |
$161.96 |
55.3% |
|
3 |
245 |
69.38% |
$292.80 |
$137.982 |
$154.82 |
52.9% |
This table compares the current cost of the EBS volumes to their cost once we adjust them to their recommended volume size (RVS). We’ll get into how to determine the RVS shortly, but for now, take a look at the percentage of free space. It starts at 73% and ticks down slowly over time. Although having 73% free space may be prudent when you’re provisioning hardware over a multi-year time scale, it’s definitely overkill in the cloud. You still want some free space, of course; we’ve found that a 30% buffer, while accounting for growth over the next three months, strikes the right balance between cost and headroom.
Check out the savings in the last column! We cut costs by more than half using the recommended volume size, while maintaining a solid buffer. Best of both worlds.
One thing to note here. This pricing calculator assumes that we resize EBS volumes for OpenSearch to the recommended volume size at the very beginning of every month. There’s no dollar cost to resize, but it’s still a change, and all change comes with some risk. For example, the cluster may enter a red status, indicating that some indices have been lost. We believe that monthly resizing strikes the right balance between AWS cost optimization and moderating the frequency of changes to your infrastructure.
If you’re using CloudFix to right-size your EBS volumes, you have nothing to worry about. CloudFix includes continuous monitoring of the cluster’s health. It will notify you if there are any issues with the instance resize, then guide you through a rollback and restore. If you’re resizing EBS volumes manually, make sure to monitor your OpenSearch cluster health and have a process in place to remediate any potential problems.
4 steps to manually right-sizing EBS volumes for OpenSearch
Fill up that cup of coffee. Here’s where it gets fun.
The process of manually resizing EBS volumes for OpenSearch involves four steps:
- Find the volumes
- Calculate the recommended volume size
- Resize the volume
- Monitor the cluster
Step one: Find the volumes
The first step is to find the eligible volumes at an account or organization level. To do this, we:
- Use the Cost and Usage Report to find OpenSearch domains with gp2 and/or gp3 storage costs.
- Use CloudWatch metrics for OpenSearch (FreeStorageSpace, ReadIOPS, WriteIOPS). Note that for AWS OpenSearch Service, you don’t need to install the CloudWatch agent yourself, it’s handled for you.
We recommend querying the Cost and Usage Report (CUR) with Amazon Athena. This allows you to run a SQL query on the CUR data. A CUR query of this type may look like:
SELECT
line_item_resource_id,
line_item_usage_account_id,
line_item_usage_start_date,
line_item_usage_end_date,
line_item_product_code,
product_product_name,
line_item_usage_type,
line_item_operation,
SUM(line_item_unblended_cost) AS total_cost
FROM
your_cur_table_name
WHERE
line_item_product_code = 'AmazonES'
AND (
line_item_usage_type LIKE '%ES:gp2%'
OR line_item_usage_type LIKE '%ES:gp3%'
)
GROUP BY
line_item_resource_id,
line_item_usage_account_id,
line_item_usage_start_date,
line_item_usage_end_date,
line_item_product_code,
product_product_name,
line_item_usage_type,
line_item_operation
ORDER BY
total_cost DESC;This query lists the spending on OpenSearch domains with either gp2 or gp3 product codes. Note that line_item_product_code and line_item_usage_type contain the ES prefix because this service was originally called Amazon ElasticSearch. The line_item_resource_id will be an ARN for an OpenSearch domain, e.g. arn:aws:es:us-east-1:0123456789:domain/cf-my-domain.
You can also use the list-domain-names and describe-domain commands using the API functions for OpenSearch. A code snippet to use is:
import boto3
# Create an OpenSearch client
opensearch = boto3.client('opensearch')
# Get the list of OpenSearch domains
domains = opensearch.list_domain_names()['DomainNames']
# Loop through each domain and check if it has EBS volumes with GP2 or GP3
for domain in domains:
domain_name = domain['DomainName']
domain_status = opensearch.describe_domain(DomainName=domain_name)['DomainStatus']
if domain_status['EBSOptions']['EBSEnabled']:
volume_type = domain_status['EBSOptions']['VolumeType']
if volume_type == 'gp2' or volume_type == 'gp3':
print(f"Domain: {domain_name}, Volume Type: {volume_type}")With either method, you end up with a list of names of OpenSearch domains. When you use the CUR, you also get the cost data and can focus on the most cost-impactful domains, so that’s our preferred technique.
The heavy lifting in this process is done by the describe-domain function. This command gives a summary of the cluster. Make sure to look for the EBSOptionsobject, as well as the ElasticsearchClusterConfig Object and the InstanceCount within that object.
{
"DomainStatus": {
"ARN": "arn:aws:opensearch-service:us-east-1:123456789012:domain/test-domain",
"Created": true,
"Deleted": false,
"DomainId": "d-1234567890",
"DomainName": "test-domain",
"EBSOptions": {
"EBSEnabled": true,
"Iops": 0,
"VolumeSize": 800,
"VolumeType": "gp3"
},
"ElasticsearchClusterConfig": {
"DedicatedMasterCount": 1,
"DedicatedMasterEnabled": true,
"DedicatedMasterType": "r5.large.elasticsearch",
"InstanceCount": 3,
"InstanceType": "r5.large.elasticsearch",
// ...
},
}
}In this example, in the EBSOptionsobject, VolumeSize is 800 GiB and VolumeType is gp3. Also, in ElasticsearchClusterConfig, we see InstanceCount is 3. This count refers to the number of data instances. So, we can see that this cluster is running three EBS volumes with 800 GiB each.
Once we know the volumes, let’s look at the CloudWatch metrics. Query CloudWatch for these statistics:
|
Namespace |
Metric |
Stat |
Description |
|
|
|
Maximum |
Number of read IOPS on EBS volumes |
|
|
|
Maximum |
Number of write IOPS on EBS volumes |
|
|
|
Minimum |
Cluster-level amount of free storage space |
For each CloudWatch query, use these dimensions:
[
{
"Name" : "DomainName",
"Value" : ""
},
{
"Name" : "ClientId",
"Value" : <YOUR_ACCOUNT_NUMBER>
}
]Note that FreeStorageSpace provides the amount of storage space available in MiBs, at the cluster level by default. By comparing FreeStorageSpace with the VolumeSize in the cluster, we can work out the percentage utilization of the cluster’s EBS volumes.
Alright – now we should have:
- A list of all OpenSearch clusters that use EBS volumes with gp2 or gp3 (from CUR or OpenSearch API)
- The cost data associated with these volumes (from CUR)
- The size of the volumes (from OpenSearch API)
- The amount of free storage space and read/write IOPS (from CloudWatch metrics)
With this data, we can identify OpenSearch domains that have “too much” free space and are good candidates for resizing.
One more thing: as mentioned above, we like to shoot for 30% free storage space to achieve a good balance between AWS cost optimization, having a buffer, and not resizing the volumes more than necessary. Your exact criteria, however, should be determined by how accurately you can predict future growth of your cluster, how often you want to resize your instances, and how much headroom you want vs. how much you’d like to save. Which brings us to…
Step two: Calculate the recommended volume size
In the pricing exercise above, our OpenSearch cluster grew at 15 GiB per month, a very predictable rate. In reality, the growth rate will be variable. When you have an unpredictable rate, you can either have even more headroom or resize more often.
Here’s how we crack this nut at CloudFix. We look at the rate of change in our storage space over the past 30 days, and then use that rate to make a prediction 90 days into the future. Let’s call this variable PFSS90. We then use the following derivation:
PFSS90
= CurrentFreeStorageSpace + 3 * (CurrentFreeStorageSpace - FreeStorageSpace30DaysAgo)
= 4 * CurrentFreeStorageSpace - 3 * FreeStorageSpace30DaysAgo
Let’s put some numbers to this. Say we have an 800 GiB volume. We start with 200 GiB used, so we have 600 GiB free. Then we begin adding exactly 15 GiB to the volume every 30 days. So, CurrentFreeStorageSpace – FreeStorageSpace30DaysAgo would be 600 – 615 = -15. In other words, our rate of change of free storage space is a decrease of 15 GiB every 30 days.
This means that in 90 days, we expect to decrease the amount of free storage space by 45 GiB, so in three months, we expect the free storage space to be equal to the current free space, plus three times the 30-day change rate. In this case, it would be 600 + (3 * -15) = 600 – 45 = 555. So, if we currently have 600 GiB free and we expect to decrease that amount by 15 GiB every 30 days, then in 90 days we expect to have 555 GiB free. That’s still too much headroom.
How can we find our Goldilocks EBS volume size, a.k.a. the recommended volume size? First, we want to figure out the minimum amount of free storage space. Let’s call this variable MFSS.
To calculate this, consider both the minimum free storage space in the past 30 days (call this MFSS30), and the PFSS90 that we just calculated. We find that:
MFSS = max(0, min(MFSS30, PFSS90)).
Let’s break this down. MFSS30 measures the minimum amount of free storage space in the past 30 days. If we’re only adding data to our index, then the minimum amount of free storage space in the past 30 days will be the current free storage space. The PFSS90 will be the smaller number, because we will continue to use space. If we’re deleting things from our cluster at a rate faster than we’re adding, then the MFSS30 will be the amount of free space when the drive was fullest, which will be on average about 30 days ago. In this case, MFSS30 will be smaller.
We want to take the smaller of these two numbers to use as a lower bound for the amount of storage space. We then make sure that this number is not negative, and if it is, we set MFSS to 0.
Going back to our example, PFSS90 = 555, MFSS30 = 615, and max(0, min(615, 555)) = 555.
Finally, we can calculate the recommended volume size using the formula:
RecommendedVolumeSize = (Current Volume Size - MFSS) * 1.3.
With this step, we take the current volume size and remove the minimum free storage space needed (taking into account the predicted growth rate for 90 days), and then apply a 30% buffer. Continuing with our example:
RecommendedVolumeSize = (800 - 555) * 1.3 = 245 * 1.3 = 318.5
Next, round this to the nearest integer (since EBS volume sizes must be GiB in integers) and get 319 GiB. Doing some napkin math, if we’re currently at 200 GiB, growing by 15 GiB per month, we would expect to be at 245 GiB in three months, so an EBS volume of size 319 is adequate. It includes a buffer for unexpected growth, but it’s not outrageously large given the amount of data we are storing. That’s what we’re going for.
For our friends with gp2:
We highly recommend switching to gp3 volumes wherever possible (and CloudFix makes it super easy to do so.) However, if you need to stay with gp2 for some reason, the calculation becomes slightly more difficult. Since gp2 IOPS and throughput scales with volume size, you may need to keep your volume size larger than it would need to be in order to reach a target IOPS or throughput. You can still run the calculation above, not considering IOPS or throughput. Then, if IOPS or throughput is not sufficient, increase the size until you reach the desired rate.
Step three: Resize the volume
Time for the easy part. Once you have your new target size, updating the cluster is fairly straightforward. Use the following command:
aws opensearch update-domain-config \
--domain-name <YOUR_DOMAIN_NAME> \
--ebs-options EBSEnabled=true,VolumeType=<YOUR_VOL_TYPE>,VolumeSize=<NEW_VOL_SIZE>Just fill in the blanks for <YOUR_DOMAIN_NAME>, <YOUR_VOL_TYPE>, and <NEW_VOL_SIZE>.
Step four: Monitor the cluster
Now that you’ve updated the domain configuration, monitor the cluster to keep an eye on it. We recommend using CloudWatch to look at the ClusterStatus.red alarm. As discussed in the documentation, “A value of 1 indicates that the primary and replica shards for at least one index are not allocated to nodes in the cluster. For more information, see Red cluster status.” This alarm can be deleted once the resize operation has completed.
(You’ll recall from above that you don’t need to download the CloudWatch agent to use it with OpenSearch. To learn more about monitoring OpenSearch Service clusters using CloudWatch, read this.)
We recommend tracking two particular CloudWatch metrics, FreeStorageSpace and ClusterIndexWritesBlocked, for the next 90 days. FreeStorageSpace is the amount of free storage space on a node of the cluster, with a value in MiB. We echo AWS’s recommendations to set this equal to 25% of the storage space for each node. ClusterIndexWritesBlocked is a “higher level” alarm. It tells you that the cluster is unable to write to disk. This often happens when a disk is full, but can also happen due to disk failures, or running out of inodes on the filesystem (sysadmin folks know what I’m talking about here).
Right-size your OpenSearch EBS volume costs easily and automatically with CloudFix
Simply changing the size of an EBS volume for OpenSearch is easy. Changing the size in a strategic, informed way, however – and therefore minimizing costs while mitigating risk – that’s where the process gets clunky.
As we saw, the target size of a cluster’s EBS volumes is based not only on the amount of free space at present, but on a prediction on the amount of free space that will be available in three months. This requires analyzing the rate of change in free space, forecasting three months into the future, and then applying a buffer policy. This analysis is not particularly hard (it’s what we explained above), but it’s certainly not the most impactful way to spend your time, and it would quickly become tedious to do it for each cluster, every month.
Not with CloudFix. We built safe heuristics into the automation, so you can always strike the balance between frequency of resizes vs. the potential for AWS cost savings. CloudFix scans your OpenSearch clusters every week and proposes any AWS cost optimization opportunities that it finds. Once you approve a set of changes for a particular OpenSearch cluster, CloudFix won’t propose any changes to that cluster for 30 days. The built-in buffer and the CloudWatch alarms that CloudFix configures also keep you prepared for unexpected changes to your cluster’s space usage.
There’s a lot of hard-earned knowledge and experience built into this finder/fixer – and a lot of potential cost savings. Skip the hassle of right-sizing EBS volumes for OpenSearch yourself. Instead, simply enable the “Shrink AWS OpenSearch volumes” fixer, evaluate and approve the changes, and enjoy the AWS cost savings… perhaps with a hot cup of coffee.
Related Articles
-
<
- AWS Cost Optimization: The Complete Guide to Lowering Your Cloud Bill (2026)
- AWS Cost Optimization Tools: The Complete Comparison Guide (2026)
- GP3 vs IO2: Up to 87% Cheaper — Real AWS Pricing Benchmarks (2026)
- GP2 vs GP3 AWS: 20% Cheaper, Faster IOPS — Full Cost Comparison
li>DynamoDB Standard-IA: Save 60% on Storage Costs (2026 Guide)